
[Two Cents #82] “Flights of Thought” on Consumer + AI — Part 8: Personalization

Introduction
It’s becoming clear that the market’s “readiness” for Consumer AI has crossed a tipping point.
What we need now is to get far more concrete about how AI-driven market change will unfold—the direction, the mechanisms, and the implications for industry structure, competitive dynamics, and the economics between participants.
For founders, the job is to identify those opportunities a little earlier and move first. For investors, the job is to recognize those early moves quickly and support them aggressively.
This series—my “Flights of Thought”—is an attempt to share how I’m thinking through what will happen, what it will unlock, and what kinds of ideas are likely to matter.
This time I want to focus on what I suspect will become the most important “hidden platform” in consumer AI: the personalization layer.
I originally wanted to lay this out before diving deeper into vertical opportunities, but personalization is harder to write about cleanly—because the market is still early, the architecture is unsettled, and most “obvious” answers don’t work yet. My thinking here is not final, but it’s mature enough to be worth publishing as a baseline.
What “personalization” actually means
GenAI made two things broadly feasible for the first time:
Reasoning and generation over massive knowledge—at a scale no individual can internalize (transformers).
Infinitely personalized generation—content, outputs, experiences—at near-zero marginal cost (diffusion for images/video; transformers for code, UX, and increasingly “vibe coding”).
We’ve already seen this arc move from images → video → and now into games, 3D/world models, and software creation. When this capability extends beyond “content” and into how consumers interact with systems—the interface, the workflow, the ongoing relationship—then personalization becomes a true platform layer.
A concrete example is the “hyper-personalized, infinite-choice, lifelong learning” model I discussed in [Two Cents #81] for education.
Even today, we can see early, crude personalization in mainstream products:
The more you use ChatGPT, the more it carries forward prior conversational context—what you’re working on, what trip you’re on, what you tend to ask for—and it starts to behave differently without being explicitly instructed every time.
As that accumulates, switching costs rise. This is the current “LLM chatbot personalization” lock-in dynamic.
If you inspect ChatGPT’s memory, it’s still primitive: it extracts a few pieces of context it believes are relevant and reuses them as prompt context. Yet even this lightweight approach already creates meaningful stickiness.
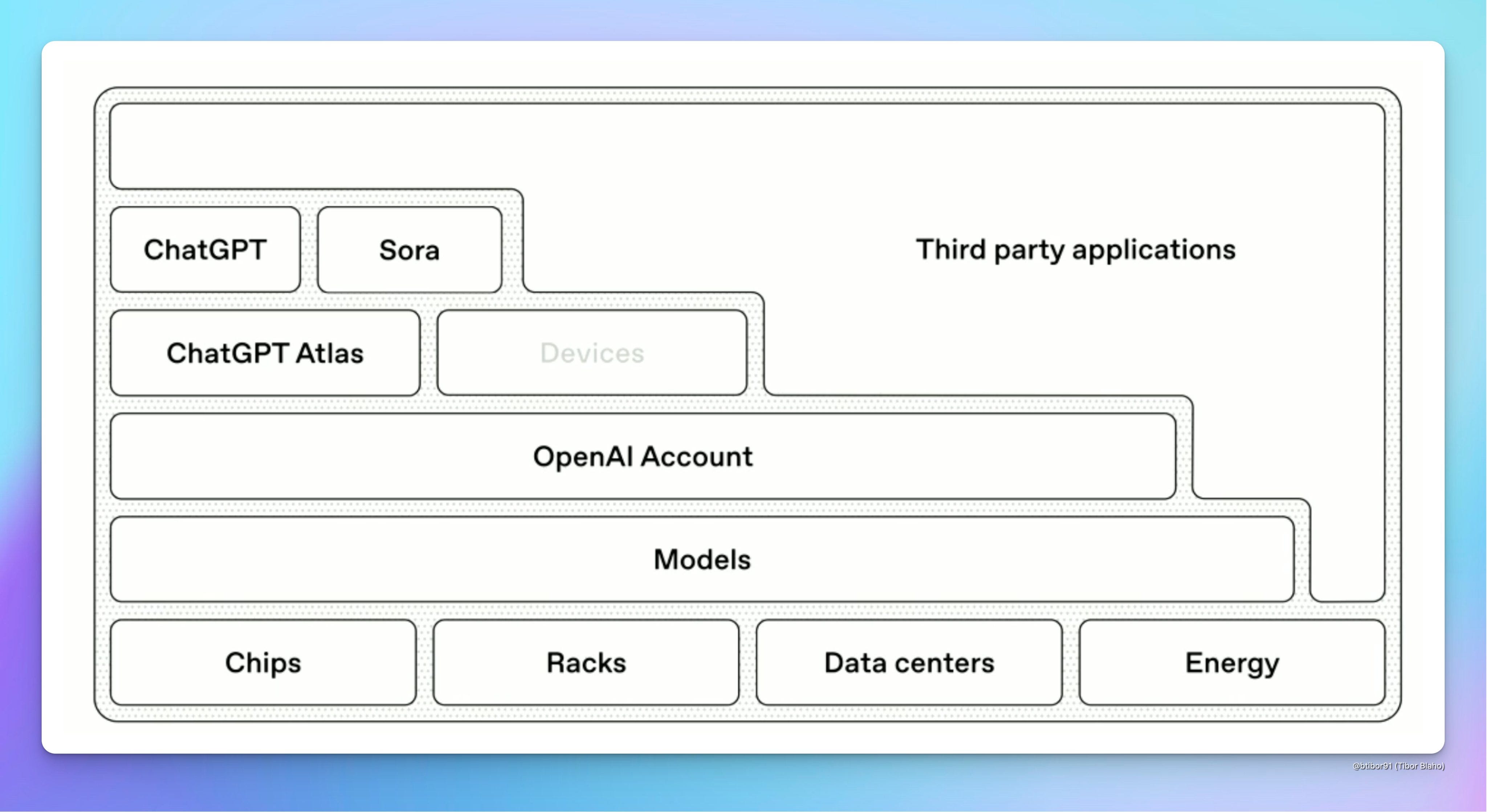
My read is that OpenAI’s consumer strategy is essentially: build personalization infrastructure, wrap it in an account, and turn it into lock-in. Today that starts with memory/context. Long-term it likely expands into a more explicit personalization data layer—which becomes core to making ChatGPT feel like a consumer “AI super app.”
If personalization expands to the whole AI “system,” what happens?
By “system,” I mean the broader AI environment: services, apps, agents, infrastructure, and eventually ambient computing contexts.
Once personalization becomes system-level, a few characteristics define it:
It understands your context (scope and depth vary).
It infers your intent—either reactively (from what you say) or proactively (even when you don’t ask).
It delivers a personalized UX that adapts over time.
It produces outcomes that feel tailored—because they are.
Importantly, this isn’t the same personalization we’ve had for the last 30 years. The depth and compounding effect are fundamentally different.
The evolution: favorites → recommendations → delegation → proactive/prescriptive
Most “personalization” historically looked like favorites—explicit saving (playlists, bookmarks).
Then it became recommendations—systems predicting what you might like based on behavior and similarity graphs.
AI-driven personalization now splits into two major modes:
1) Delegation / autonomy (reactive personalization)
You delegate tasks to a system that “knows your context.”
“Find a dress for this weekend’s event that fits my style.”
“Plan and book a 2-night family trip, including my youngest.”
The key is that you’re no longer selecting from menus; you’re delegating outcomes.
2) Proactive / prescriptive personalization
An agent that knows your context begins to surface tasks before you ask.
“Next weekend your youngest has a school event. You’ll need X items—should I order them now?”
“Your calendar suggests travel next week; do you want me to adjust your routine purchases and deliveries?”
This is where personalization starts to look like an ambient “butler agent,” not a recommendation widget.
What form does personalization take?
I expect personalization to manifest through multiple building blocks:
Personalized agents
Per-system personalization: each service remembers your interaction history.
Per-person personalization: one “lifetime partner” agent carries your context across services, delegates work outward, and nudges you proactively.
“Conformative software”
Software that adapts its behavior and UX over time based on how you interact with it. Today’s ChatGPT personalization is an early, minimal version of this.
On-device vs. cloud-based
Some of your personalization may live on-device (privacy, low latency, continuous capture).
Some will live in the cloud (ambient agents, cross-service execution).
Collective memory
Personalization won’t stop at the individual. We’ll build shared context layers for:
families
teams
organizations
This becomes “collective memory” that enables group-level personalization.
Why personalization becomes the strongest lock-in mechanism
As personalization accumulates, lock-in grows in two directions:
Users will prefer systems that remember them.
You’ll never want to be a stranger to a new agent or AI app.
Personalization compounds.
Every decision you make becomes training data for the system’s future usefulness. The benefits increase with time, which strengthens retention loops.
In this world, personalization effects can become as powerful as network effects—sometimes more powerful, because they attach directly to the individual’s daily workflow and identity.
The data required for personalization
The data spectrum is broad, but not necessarily exotic. A rough stack:
Level 1: email, calendar, documents/files
Level 2: social graphs + messenger history
Level 3: commerce + delivery + banking + card transactions
Level 4: real-time location trails (e.g., maps history)
Level 5: health data (e.g., iCloud/Apple Health)
Level 6: real-time conversations/calls + screen/tap/click streams
Level 7: TBD
The bottleneck is not imagining the data—it’s acquiring and using it:
How does a service legally and practically access these layers (especially Level 4+ in real time, which is extremely difficult for third parties)?
How do you merge and transform the data into something that creates felt personalization value?
How do you do this while preserving privacy, trust, and user control?
Where the industry is, technically
A useful simplification of agent systems: state (memory/context), model, actions (tools/servers).
Most products today are still largely:
stateless agents, or
one-shot workflows.
The frontier is building stateful agents—systems that can manage memory over long horizons, maintain consistency, and improve over time.
This is why “sleep-time compute” matters: agents doing background work—organizing memories, analyzing patterns, preparing proactive suggestions—without explicit user prompts.
A key idea here is: the agent can outlive the model. Models will be upgraded frequently; the user’s long-lived agent identity, memory, and personalization layer cannot reset every time.
To make true stateful agents work, we likely need something closer to a context OS—the “context engineering” direction Andrej Karpathy has pointed at.
Early attempts and what they teach us
The next “personalization data layer” architecture is not settled. Everyone is experimenting with different workflows, UX patterns, and data-layer models.
A few examples from recent history:
Rewind tried capturing screen-level activity (“digital time machine”), ran into privacy + unclear everyday value, and pivoted (now Limitless) toward conversation/meeting capture.
mem0 is pursuing a memory layer that records digital activity and builds a personal knowledge base.
Letta is building tooling to create agents with “memory.”
Poke.com is experimenting with building a personal context layer and delivering a consumer-facing personalized assistant.
A pattern emerges: building a horizontal personalization data layer is a classic early chicken-and-egg problem. Before you have enough data, it’s hard to deliver a product users truly feel. Without that felt value, you can’t scale data collection. Without scale, you can’t become a platform.
That likely explains why “data layer first” attempts often stall.
The more promising strategy may be the inverse: start with a sharp, high-value product where users willingly contribute data, reach critical mass, then gradually broaden the personalization layer horizontally. Poke.com hints at this path.
This resembles how massive networks like Facebook or Kakao built dominance: not by starting as “infrastructure,” but by winning with a single wedge product and then compounding data advantages over time.
“Next Google”
If someone does build a true consumer-grade personalization data layer—horizontal enough to sit beneath many services—its power could exceed what Google achieved in Web 1.0.
In an agent-native world, the ratio of what consumers do themselves vs. what they delegate could flip dramatically—from something like 90:10 today toward 20:80 (or even 10:90).
The personalization data layer becomes the enabling infrastructure for:
the best “personal concierge” agent, and
the deepest, compounding lock-in loop.
The end-state looks like the cultural archetype: Her’s Samantha, or the classic “butler” who understands your intent better than you can articulate it—and executes reliably.
Whoever owns that layer could become the primary consumer entry point, with lock-in dynamics that compound more strongly than search ever did.
That’s why I believe the personalization data layer / agent category could produce a dominant consumer platform on the scale of Google—or potentially larger. The exact form will evolve dynamically over the next decade, but the strategic direction feels clear.
Call for Startups
The purpose of sharing this thinking is straightforward. As an early-stage investor focused on Consumer + AI, I hope this series helps existing startups better leverage AI-driven shifts—and helps new founders reduce trial-and-error as they search for meaningful opportunities.
In that sense, this is Two Cents’ version of a Call for Startups.
If you are an early-stage founder or startup in Consumer + AI and believe you are onto something, my inbox is always open. Feel free to reach out via DM or email:
hur at hanriverpartners dot com